
Cloud-native GIS – what is the actual definition?

Lately, I have been discussing the concept of modern GIS, and while it doesn’t require the cloud to run (in fact a core principle is that it can be run locally or in the cloud) it does allow you to easily move to the cloud when ready.
With that said not all things in the cloud are made equal. There are many ways to use the cloud, but some paths will get you more scale and speed with less effort than others.
In this post, I will discuss those different options, with an emphasis on unpacking the term cloud-native GIS: what it means and why it may be beneficial to your workflows.
In short:
A true cloud-native GIS workflow allows you to achieve massive analytical scale by auto-scaling your resources with serverless workflows, without direct management of compute resources, and leveraging parallel processing to analyze and work with massive geospatial data.
Examples of GIS in the cloud
GIS and maps have been running in the cloud and on the web since the cloud (and the web) have been around. If you want a very detailed history of this, check out my post on the topic of web maps. Simply put, GIS running in the cloud is the ability to access spatial applications and analysis from data or services hosted in the cloud.
A few examples of GIS running in the cloud might be:
- A web map showcasing flood zones in your city
- An API serving data from a spatial database
- A virtual machine running a formerly desktop service
- A spatial database running on the cloud
- Running Python notebooks in a cloud environment
- Storing Cloud Optimized GeoTIFFs in a cloud storage bucket
- Running analysis on a data warehouse
But simply running in the cloud does not make your geospatial workflows cloud-native. Let’s discuss why.
A quick side note
This post will primarily focus on the technology aspect of cloud-native GIS but there has also been a significant discussion around the supportive file structures to better support cloud-native technologies.
This includes things like GeoParquet, Zarr files, Cloud Optimized GeoTIFFs, and more. Check out this talk from the Cloud Native Geospatial Outreach Event from the Open Geospatial Consortium:
3 types of GIS in the cloud
In my opinion, there are three types of GIS in the cloud
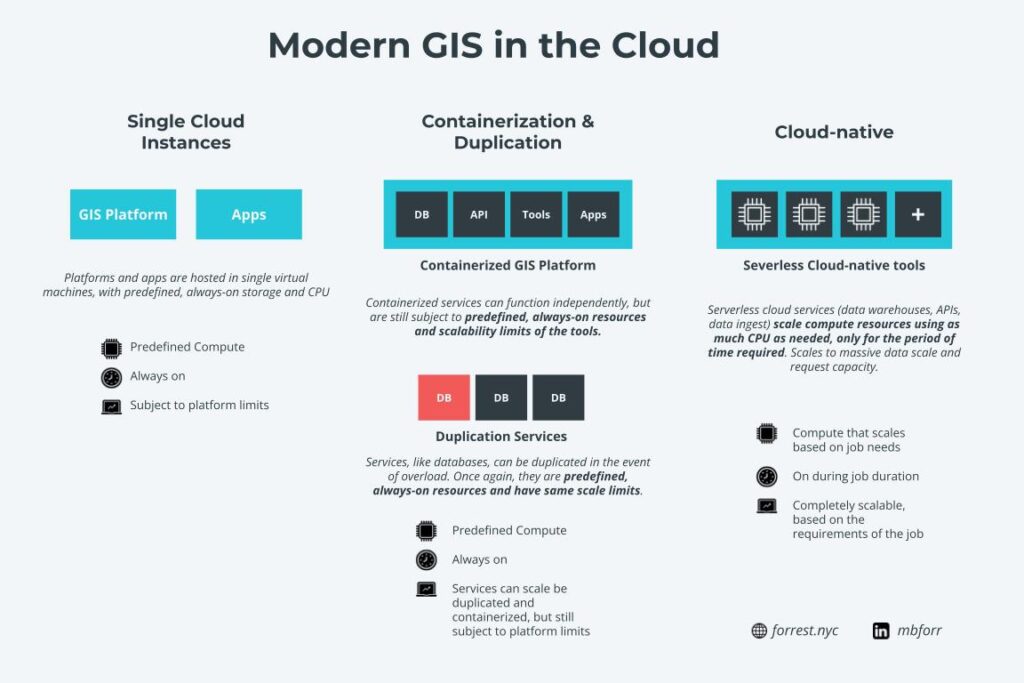
There are three points that I used to evaluate these different services:
- Compute scalability: How scalable or elastic are the computational resources for the service?
- Serverless capabilities: Does the service allow for serverless, meaning no provisioning or management of servers?
- Parallel scalability: Can the service scale in parallel to process large-scale operations?
If you are not familiar with these concepts, I would recommend checking out this whitepaper by Google Cloud that explains some of the concepts around serverless and parallel processing as well as this intro to BigQuery, which will lay some of the groundwork for you.
you manage and analyze your data with built-in features like machine learning,
geospatial analysis, and business intelligence. BigQuery’s
serverless architecture lets you use SQL queries to answer your
organization’s biggest questions…
Single Service or Application
The most common way that GIS runs in the cloud is the deployment of an application like a web app, micro-service, database, or any combination of services in a single virtual machine or another cloud service (such as a deployment framework like Firebase or Surge).
If you are not familiar, a virtual machine is just like your computer in that it has a predefined CPU and storage, but it (generally) has no predefined operating system and it runs on the cloud. Many times however you will use a service a cloud provider has built to deploy these services: there are database services, application services, and hosting for APIs and Jupyter notebooks.
So how do these single services fit into our cloud-native evaluation framework?
| Compute scalability | The compute services in a single service or application are fixed, and while they can be modified they generally require a service shutdown and redeployment. |
| Serverless capabilities | These services require manual provisioning and management and are not serverless. |
| Parallel scalability | Generally, these services are not scalable in parallel unless the data service is by nature (i.e. Spark) |
In short, these services, while running in the cloud, are not cloud-native by design.
Duplication or Containerization
The next services we will evaluate are orchestrated cloud services such as duplication or containerization. These services require less management than single application services, but still, require some level of management.
Duplication
Duplication services are just as the name sounds, services that duplicate when required. Let’s review a practical example.
Imagine we are a local government in Florida and we maintain a web map that shows current flood gauges and flood zones. It may receive a few hundred visits a day and the application database, while small, is well suited for the demand.
A few days later, a hurricane is forecasted to make landfall in your area, and the application steadily receives more visits, and all of a sudden it is now receiving hundreds of visits every few minutes, until the database stalls and crashes as it cannot support the demand.
Duplication can solve this problem. Using orchestration services like Kubernetes, you can tell your service to duplicate itself based on demand. This will allow your service to scale with spill over services should demand suddenly increase.
However, there are still limitations to this as the duplication services are still subject to the limits of the service itself, meaning that if the database can only handle 20 concurrent queries, you are still subject to that limitation. Additionally, these services will be continually running until they are shut down but the orchestration process.
| Compute scalability | The compute services in a duplication service are fixed and subject to the limits of the service design (i.e. if your duplicated services are given 16 GB CPU, then that is what they will remain no matter how many times you duplicate them) |
| Serverless capabilities | These services are semi-serverless. You are still responsible to define the duplication process, but once defined the services will duplicate based on the parameters you have given. |
| Parallel scalability | Generally, these services are not scalable in parallel unless the data service is by nature (i.e. Spark) |
Containerization
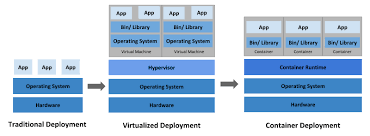
Containerization is a method of “containing” individual services in individual virtual machines or other services. In the older world of software deployment, every part of an application was packaged into one giant deployment: application interface, database, APIs, data, etc. So in this case, if one thing went down, it took the entire service down with it.
Containers helped to solve this problem. Each service can be put into it’s own container, running in an environment with only the code or operating system that it needs. If one service goes down or needs an upgrade/repair, then you can turn that service off and fix it and all the other services will remain up and running (although they couldn’t access the service that is shut down while it is shut down.)
This solves many problems from an IT maintenance perspective, yet it is still not cloud-native.

| Compute scalability | The compute services in a containerization service are fixed and subject to the limits of the service design, meaning that if your database has a limit of 2000 rows that can be queried via API, that limit remains |
| Serverless capabilities | These services require manual provisioning and management and are not serverless. |
| Parallel scalability | Generally, these services are not scalable in parallel unless the data service is by nature (i.e. Spark) |
☁️ Cloud-native
Now we get to the true cloud-native approach. These services meet all the thresholds we have laid out. Let’s take a look at the different areas in detail and also match this with some different services that meet the cloud-native threshold.
While these different measures might look different depending on your process, they are applicable across many operations: database/data warehouse queries, ETL and ingestion processes, applications, and more.
| Compute scalability | Compute services scale as need demands, and while limits can be placed, there are no predefined compute services and they are scaled based on need. |
| Serverless capabilities | Services are completely serverless, meaning there is no provisioning or management. |
| Parallel scalability | Processing services run in parallel, based on the requirements of the job. |
Compute scalability
The first benchmark is compute scalability. This means two things:
- You do not pre-define the compute needed for your application or data
- You do not need to manually allocate more compute resources
For example, in a data warehouse if you enter a query, the data warehouse will allocate the proper amount of resources to run that query, no matter if that is a small or large amount of computing resources.
This is the first hallmark of cloud-native. You are hands-off in terms of deciding the amount of computing resources needed for your operation and the system will also automatically scale this for you as needed.
Serverless capabilities
Next, we will take a look at serverless capabilities, meaning that there is no management or provisioning of resources, you just use the service and it manages those aspects for you.
Today more and more services are adopting this practice of auto-scaling compute services, adding more resources as the job demands. This works great for many uses cases and alleviates the need of direct management of virtual machine and compute resources which generally requires assistance from other teams responsible for managing cloud infrastructure.
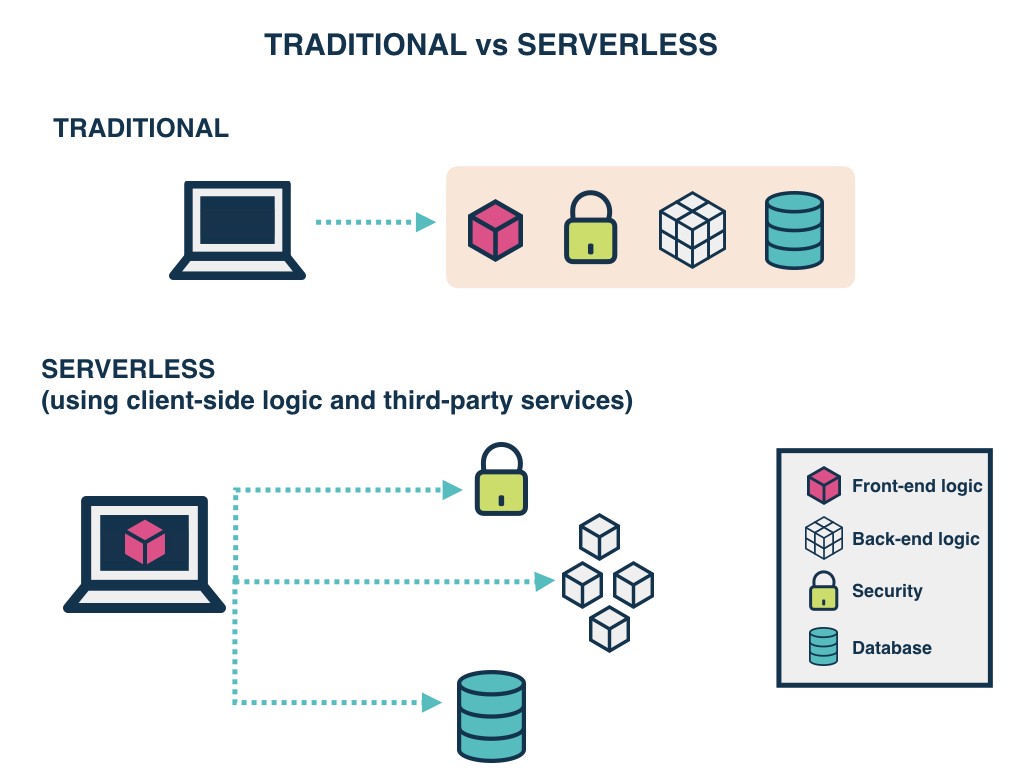
However, in some cases, you may want more fine-grained control over how many resources your process uses. Using orchestration tools like Kubernetes you can manually decide on how those resources should scale.
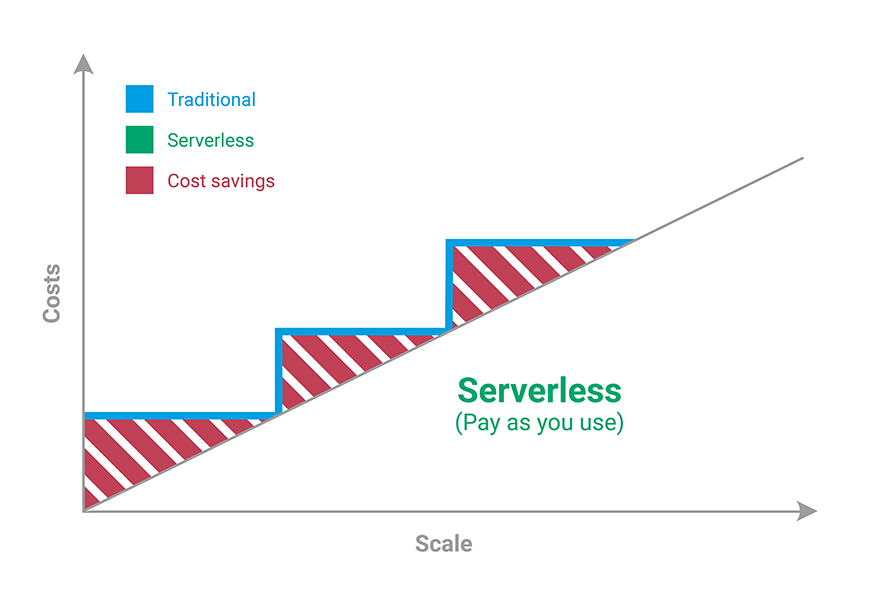
The key advantage here is that you use what you need, then those compute resources are shut down. In simple terms, it is the difference between owning a car and using Uber.
When you own a car you are responsible for it and pay for it no matter if you are driving it or not. You cover the maintenance and risk. When you use an Uber you can simply ask for the service when you need it, and you can pick the type of service you want.
In a serverless setting, you just rent the resources you need for the time you need them, and then once you are done you don’t continue to pay for them. In a normal setting, you pay for the resources around the clock, no matter if they are being used or not.
This second tenant of cloud-native GIS means that you can have as much control over your resources or be completely hands-off, but enjoy massive scale as required.
Parallel scalability
Finally, parallel processing allows for different large scale processes to be split up and processes in parallel. This more often applies to databases/data warehouses and data pipelines than other processes.
Parallel processing means that a job or process, instead of being run in one job end to end, essentially it splits it into smaller chunks, and once done it reassembles.
So a job that may take an hour to run, can be split into many smaller chunks and can complete in minutes or seconds. In many cases, but not all, this really stands out in aggregations which can see some major boosts in performance. I’m the spatial world this usually means spatial joins.
This last core principle opens up lots of use cases, especially those that may not have been accessible earlier if you had a siloed GIS system. Now you can integrate and aggregate geospatial data with the massive datasets being generated across enterprises today.
🚀 Other emerging trends
In addition to these points there are a few other developments that are worth calling out.
Columnar data storage
You can take a look at my last post about GeoParquet but this is showing up more and more. Many data warehouses use this data storage scheme and this is starting to be applied to traditional databases like PostgreSQL.
Raster
One of the first true cloud-native initiatives in Geospatial was cloud-optimized GeoTIFFs. You can read more about this here but raster continues to be in a evolving space in the cloud. File types like Zarr and others continue to innovate and how raster data can be used efficiently both locally and in the cloud.

Spatial Indexes
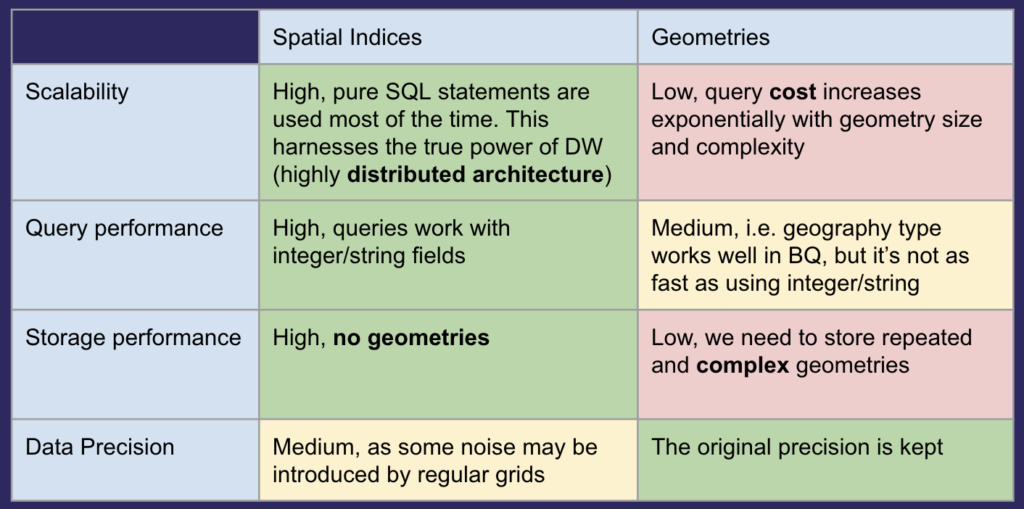
This is one of my favorite areas to explore in the cloud and deserves a post of its own. Spatial Indexing methods like H3 and Quadkey effectively allow for spatial joins without the spatial join allowing for massive gains and query performance and visualization efficiency.
With spatial indices you can break your data into these grid formats allowing them to be in smaller pieces and effectively store your geometry‘s in strings or integers. If you do this across all of your data it becomes very easy to aggregate as well as to join to other geometries that have also been broken into spatial indices as joins in SQL are far more efficient on strings or integers compared to true spatial joins.

Ironically you may end up creating more data in terms of the number of rows but the performance gains you will see pools in visualization and queries are monumental. You do lose the complete accuracy of your geometry but when done properly you will not lose any data granularity.
Geospatial data engineering
This is one of my favorite topics in geospatial currently as I believe with the amount of data being produced in GIS as well as across companies and organizations, geospatial data engineering will become as important as ever.
Geospatial data engineering certainly uses core languages and libraries that have been used for a long time such as GDAL and others, but can scale to massive amounts of data using cloud-native processes.
Examples
More and more services are adopting a true cloud-native GIS approach but to give you a few ideas here are some examples of some things that you can do with a cloud-native approach for modern GIS:
- Almost all data warehouses use a cloud-native GIS approach including serverless scaling, parallel computation, and the ability to scale computational resources
- If you are creating geospatial microservices, such as an endpoint to see a fun district that you live within using latitude and longitude coordinates, different function-based services like Google Cloud Functions or AWS Lambda Functions allow you to create very scalable and serverless APIs and microservices
- Data engineering pipelines and services either using managed services like Kubernetes or completely serverless tools like Google Cloud Dataflow can be used to create scalable data ingestion pipelines for streaming and batch data
- Application deployment frameworks are also adopting serverless processes that allow them to scale to meet demand. Google App Engine is one example of this
Give it a shot, especially if you are having issues with data scale and automation, cloud-native GIS can help open up some of the most complex use cases in modern GIS today.


