
What is Modern GIS?

The GIS we use and practice today is fundamentally different from the GIS we used previously. In the past, I have written about the need to define geospatial as a practice, and yet again I think it is time to define another term in our space.
Modern GIS is something that is starting to take hold and define itself as both new technologies and tools are being developed, new ideas and skills are being taught and learned, and more processes are using cloud-based tools and services (although this is not a prerequisite of modern GIS).

The Spatial SQL Book – Available now!
Check out my new book on Spatial SQL with 500+ pages to help you go from SQL novice to spatial SQL pro.
What is Modern GIS?
So, what is Modern GIS? Below is my definition:
Modern GIS is the process, systems, and technology used to derive insights from geospatial data. Modern GIS uses open, interoperable, and standards based technology. It can be run locally or in the cloud and can scale to work with many different types, velocities, and scales of data.
Later in the post, I will break down each of these points in more detail, but I think it is important here to acknowledge the difference between modern GIS and geospatial.
GIS and modern GIS comprise of the tools and technology, or the systems that enable the work or practice of geospatial.
Geospatial is the actual execution of that work and the education, professional, and other infrastructure that enables individuals to perform and advance their professional development.
In short, GIS is like a toolbox full of tools, and geospatial are the skills and ongoing learning that teaches you how to use the tools as well as the community that shares ideas on how to use those tools as well.
GIS has had a long history and has grown and changed over the course of those 60+ years, but modern GIS, while very similar in the fact that they both represent the tools and systems to perform geospatial analysis, is fundamentally different for many reasons, and thus separate into itself.
How are Modern GIS and geospatial related or different?
Modern GIS is more open, scalable, collaborative, and accessible than traditional GIS. It can be run on a single machine with an internet connection using locally hosted open-source tools up to supporting a complete enterprise architecture in the cloud.
It supports much larger scales and velocities of data, with faster compute and processing times than traditional non-serverless workflows and the interoperable nature of open tools and common languages allows for a collaborative workflow with non-GIS teams.
This chart gives a high-level view of the differences between the two:
| Traditional | Modern | |
|---|---|---|
| Standards | Platform and software-based | Open and standards-based |
| Cloud Access | Cloud-hosted or on-premises | Cloud-native |
| Deployment | Local software package up to enterprise software packages | Open-source local use up to full enterprise |
| Collaboration | Siloed | Interoperable |
| Scalability | Single-threaded | Serverless |
| Data | Limited data scale | Scalable, even further in the cloud |
Let’s dive into each one in more detail:
What defines Modern GIS?
In short, modern GIS is defined by its open and standards-based approach and the ability to scale – to massive amounts of data as well as in computing resources, oftentimes in a serverless model.
This differs from a more traditional GIS platform that uses more proprietary systems that can scale via duplication (if one database or server becomes overloaded, a duplicate server can be stood up) but can’t scale to the same level of data volume as other cloud-native tools like data warehouses.
Below are the most important points that delineate modern GIS in my opinion.
Open and standards-based technology
The first key point is that modern GIS leverages open-source technology and develops tools that follow the conventional and practiced standards within those open source tools.
An example of this could be the use of open-source visualization libraries. Deck GL has fast become a popular choice for visualizing data within frontend applications. Rather than building new libraries to visualize and style geospatial data, we are seeing many organizations both use and contribute back to this open-source project and integrate it into their commercially focused tools and platforms.
This approach allows individuals and organizations using these tools in a free and open-source model to benefit from the organizations contributing and using these tools. The enterprise organizations that support these projects are able to avoid building proprietary tools and gain user adoption of these libraries.
This happens time and time again across many different tools, and this is a foundational component of modern GIS. The entire community benefits from cross-collaboration and common standards.
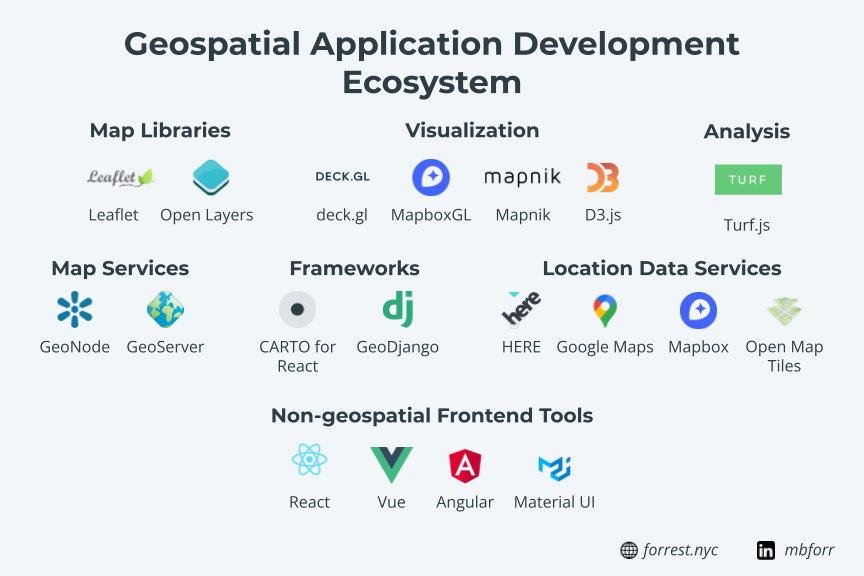

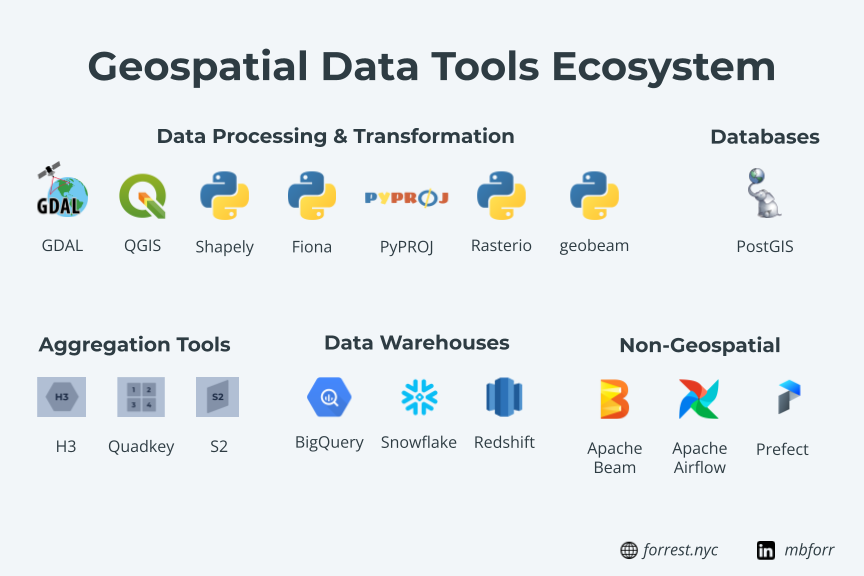
Integrated and interoperable tools and languages
Traditional GIS relies often on proprietary tools, that often use common languages, but only as a way to connect to the same proprietary tools, services, and databases.
Modern GIS is built on the foundation of using interoperable tools and languages that can be used as stand-alone tools, or integrated to work alongside other common tools. It also uses common and accepted languages and foundational components to those languages.
For example, one might use Geopandas for geospatial analysis and data processing. Geopandas follows many of these conventions:
- It is built in Python and follows the same development principals as all other Python libraries
- It is built on and uses other foundational libraries such as Pandas, Fiona, PyProj, Shapely, and more
- It extends common and accepted norms such as the Pandas DataFrame (to make the GeoDataFrame)
- It uses common installation tools like PyPI
- It uses open source development and contribution models
You can also integrate Geopandas into an API service you are building in Python because, after all, Geopandas is just a Python library.
Since all of these libraries use common languages like SQL, Python, Javascript, and more, they are also completely interoperable – meaning that non-geospatial users can use and read the same tools since they are in the same languages, and code is seamlessly shared amongst common teams.
For example, a data scientist can work seamlessly alongside a spatial data scientist. A data engineer can work seamlessly alongside a geospatial data engineer. And so on.
This not only fosters collaboration but enables everyone to work with spatial and non-spatial data alike.
Scalable, both locally and on the cloud
Modern GIS also provides scalability to work with larger data, more complex analysis, and workflows. This happens at small scales with individual users working on their own machines, all the way up to the largest enterprises using cloud-native serverless processes.
This of course looks different for each of these ends of the spectrum. For the individual user, they can scale their analytical ability locally by using indexes on their database, extending their Python workflows with PyGEOS, and creating containerized environments with Docker.
In a mid-tier, a mix of cloud or hosted services can be used for data storage and management, ensuring data access and continuity alongside local services such as desktop tools like QGIS, local Jupyter notebooks, and local development of dashboards and applications.
On the highest level, complex enterprises can use geospatial libraries and tools along with cloud-native services to manage complex batch and streaming data ingestion with geospatial data engineers in tools like Apache Beam, and serverless support for those tools like Dataflow with geobeam.
Data warehouses can store and query large quantities of geospatial data right alongside other data from across the enterprise. Tools and platforms like CARTO can be used to visualize data and make dashboards and complex applications. And hosted notebooks can provide scalable compute resources for complex processes.
The serverless aspect allows these organizations to use large amounts of computing resources for the short period of time they need them, rather than having these services running (and paying for them) all the time.
Cloud-native
Similar to the points above, modern GIS can start at a very small scale – one person with a single machine – up to very large scales. The cloud is the optimal place to run these processes for many reasons, but how you leverage the cloud can look different depending on the process you need to complete.
Traditionally, GIS in the cloud meant the hosting of data, databases/servers, sometimes tools, and applications/dashboards. While these things are all happening in the cloud, they are not scalable.
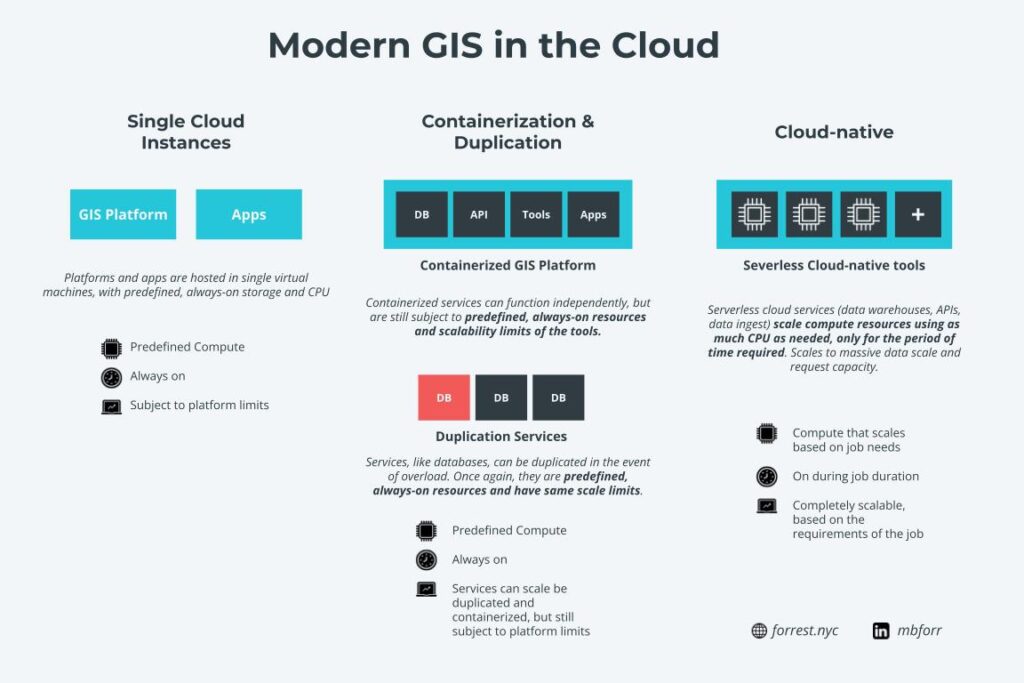
For example, a server or database running in a compute instance or virtual machine in a cloud service is always constrained by the parameters of the instance or machine it’s running on (i.e. a database running on 16 CPUs will always be constrained by those parameters unless those are manually changed).
Recently, I have seen more services start to adopt are more modern deployment model in the cloud leveraging tools like Kubernetes and Docker. And this is a good thing as it allows for the separation of services (if one component goes down, the rest of the system stays intact) and duplication of services (if a server becomes overloaded, a duplicate can be started automatically to handle the increased load – imagine a flood map app that suddenly gets many views due to a hurricane).
However, there are still two concerns here. The first is that these efforts are still supporting non-scalable services. The same servers and databases you used before are still subject to the same constraints, such as file size, processing speed, row limits, etc. as they were before. They are just easier to use now if there are any faults or if the load on the services massively increases.
The second is that these services are still always on. Meaning no matter if they are being used or not, you are being billed to use them around the clock. If you need more compute or storage resources, you can increase that, but of course, that will increase costs.
Cloud-native on the other hand uses serverless tools and services. Serverless is defined as follows (borrowed from Google Cloud):
Serverless means no upfront provisioning, no management of servers, and pay-what-you-use economics for building applications.
In practice what this means is that for the services you use, you are not in charge of provisioning the resources needed to use them. Additionally, the services scale based on demand. If you have a larger query or larger data ingest process, it will provide more compute power for that specific job. The services can determine the appropriate resources needed, provision and use them for just that job, then shut them down. What this means is that you get the appropriate amount of resources to process your job and use them just for that time you need.
This is where we start to see the definition of cloud-native GIS start to form, which is directly linked to modern GIS. It allows for modern GIS workflows and processes to be moved into integrated cloud environments, with multiple services and tools that are directly integrated, and makes use of highly efficient and scalable serverless processing.
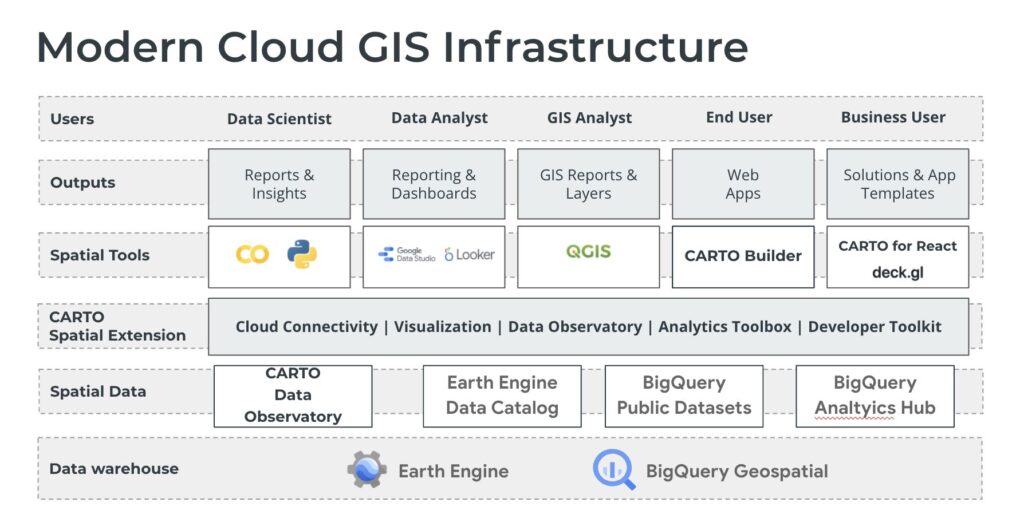
In the past, open-source geospatial tools and services were difficult to support in an enterprise setting. You either needed a dedicated team of both users and IT professionals to use them, sometimes alongside other commercial tools, or you needed a dedicated team to help you implement, and more importantly support the open sources tools.
This is now far easier. Cloud providers provide the scalability, support, security, and SLAs many large enterprises require while allowing you to use modern GIS tools and services at scale.
Ready for all types, sizes, and velocities of data
Another major advantage of modern GIS is the ability to work with any type of data. Geospatial data comes in lots and lots of formats. Hundreds, in fact, based on the number of file types supported by GDAL. GDAL is a foundational component of modern GIS architecture as it lives inside so many critical tools: QGIS, Geopandas, Fiona, and more. This one core library, built for fast and reliable performance, makes sure that modern GIS can work with any file type.
Filetypes are just one measure of data scalability and flexibility. The file size is of course another measure. This could be in terms of the number of rows of data, the number of columns, geometry complexity, or all three. Modern GIS tools allow you to scale to very large datasets, even locally. You can use different tools to read and store your data, like local installations of PostGIS or with libraries like Fiona or Geopandas. And you can take this further by using Apache Feather file formats or Dask.
In the cloud, this can be scaled even further. You can both store massive amounts of data but also make it easy to ingest. Cloud providers make tools for this that are directly integrated into data warehouses, or other data ingest tools that can be used for more complex workflows. I have done this several times with Dataflow plus geobeam, which uses core libraries like GDAL, Fiona, and rasterio, to parallel process massive datasets, including raster data with billions of rows (pixels) and terabyte-scale files.
But of course, you also have to account for streaming or high-velocity data. Fortunately, there are both local tools that can help you process this data as it comes in, but also cloud providers make this simple with tools like Apache Beam (which can be run locally or in the cloud) and other Pub/Sub based workflows. This helps you not only handle the incoming data, but also add value to the data (maybe geocoding, enrichment with census data, or measurement to nearby points), then store that data in a database or data warehouse.
Analytics on streaming or real-time data is a hot topic, and one I expect to grow, and modern GIS is ready to handle and address these use cases.
Supports new functions and roles
There are a number of new roles and functions that are starting to take shape in the geospatial space recently. As geospatial needs are growing, more focused and defined job functions are being defined and required, and the geospatial “jack of all trades” now requires a large set of skills.
Roles like GIS Analyst and even Geospatial Developer are quite common and have existed for some time, but newer positions like Spatial Data Scientist and Geospatial Data Engineer have started to emerge.
And more than likely new roles will continue to emerge. In the Data Science space, new roles such as Machine Learning Engineer, Data Architect, and others have started to become more and more common.

Modern GIS tools allow for these roles to:
- Have complete flexibility and scalability over their work
- Collaborate with similar peers and technologies in non-geospatial areas of focus
- Have interoperable code to share across teams
- Start small and scale to cloud processes
- Develop and build upon foundational tools and best practices
- Develop unique workflows, libraries, tools, and solutions on their own
More and more these roles will continue to define themselves, and more and more will develop their own processes, norms, and technologies to support the work they are doing. And modern GIS provides the foundation for that work to begin.
Outputs of many types
The final aspect of modern GIS is the different types of outputs and deliverables that can be developed. I have written about this before in my post about geospatial – but the concept is that modern GIS enables geospatial users to build the outputs that are required of the business case, rather than being limited by the outputs available to them. This list is quite long, and showcase the sheer scale of options available in modern GIS:
- Dashboards and data viewers
- Jupyter notebooks
- Simple maps for presentations
- APIs and microservices
- Data pipelines
- Simple applications
- Full stack web apps
- Integration into other systems
- Mobile applications
- Data collection and validation
- Machine learning models
- Simple static maps
- Data monetization solutions
This sheer flexibility and number of possible options is a core tenant of modern GIS. This ensures that modern GIS users are never limited or constrained in the outputs they need to create. Technically, these tools and solutions are not siloed, but fully integrated and available to use as stand-alone tools or integrated solutions.
It enables geospatial solutions to be totally integrated into the organization and most importantly, a critical part of problem-solving happening in these organizations, both at a practical and technical level.
Modern GIS is still evolving, and will change and evolve over time, but I believe these core principles and ideas will be the base from which it grows and help support a new generation of geospatial users. It is an exciting time to be in the space, and there have never been more possibilities across the geospatial space.


