
What is spatial SQL?

Spatial SQL is not just a query language. It is becoming far more than that and its uses are expanding beyond just a database for spatial data. It allows for faster spatial analysis, supports spatial applications, enables spatial data science and machine learning, and far more.
Because of these reasons I wanted to share a new definition of spatial SQL that better encompasses the true scope of what can be done with spatial SQL.

The Spatial SQL Book – Available now!
Check out my new book on Spatial SQL with 500+ pages to help you go from SQL novice to spatial SQL pro.
Spatial SQL is an interoperable language for working with spatial data enabling geospatial analysis, spatial data science, application development.
It provides GIS and geospatial users the ability to work in the same location as other data in databases and data warehouses, removing the traditional silos between GIS and other areas of an organization.
Spatial SQL supports advanced operations such as spatial modeling and machine learning in the same location that the data resides.
Maybe not what you were expecting? Most definitions would offer something like this:
Spatial SQL uses all the same elements and structure of normal SQL but allows you to work with another data type: a GEOMETRY or GEOGRAPHY
That is from my article a few months ago on why you should use Spatial SQL, and even between then and now, my view of spatial SQL has changed in a big way.
How has spatial SQL changed?
Spatial SQL is evolving from a component of a database query language into a truly interoperable component that is integral in a modern GIS and geospatial stack. To understand exactly how this is changing, let’s take a look at the wide range of use cases spatial SQL covers and the roles that might use them:
A database administrator might use spatial SQL to store, manage, update, and provide access to geospatial data to end-users across multiple database instances (the more traditional case for spatial SQL). They might use the database to create stored procedures and triggers to update data as it comes in, and automate things like projections, data manipulations, formatting, etc. The database may also be connected to other tools to allow users to view, query, and access that data. They likely work with the database through tools like pgAdmin or psql on the command line in PostGIS or with UI/command-line tools for cloud data warehouses.
A GIS analyst might be an end-user of data stored in a spatial SQL database, using the data for querying, analysis, and visualization. They use datasets alone or in combination to surface insights using spatial relationship functions in spatial SQL and other analytical tools. They generally query the data and do not make updates or changes to data, unless they make their own copies of the data. They access and visualize the data through Python, Jupyter notebooks, QGIS, CARTO, and other tools.
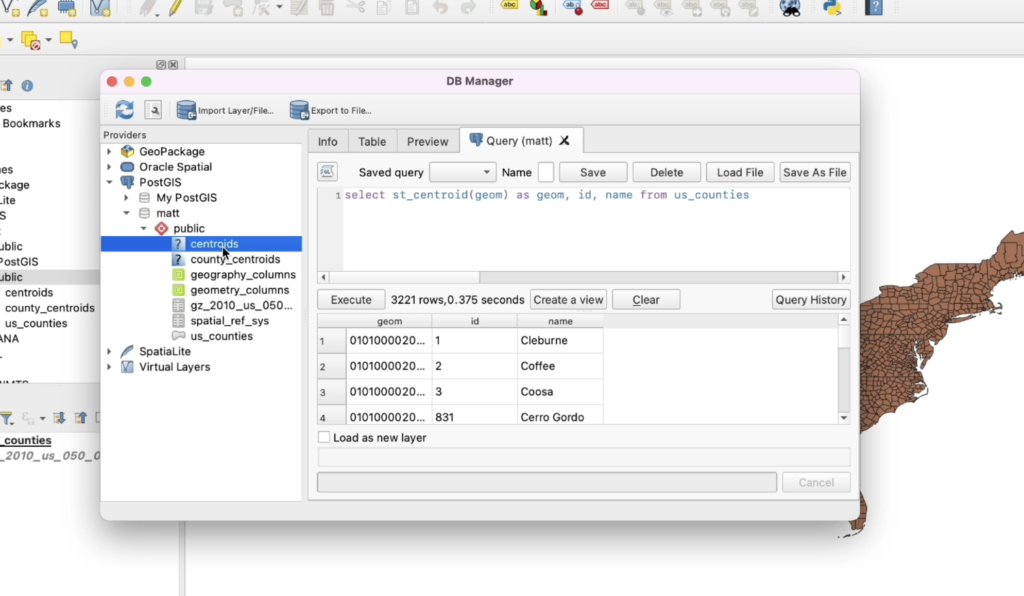
A spatial data scientist uses spatial SQL for any number of uses cases. This includes pulling data from databases to use in Python analysis by joining data to other spatial or non-spatial datasets. They may also use more advanced SQL concepts to perform rankings, window functions, spatial clustering, aggregations, and spatial relationships that are more efficiently performed in SQL. They may also use spatial SQL to analyze spatial relationships and perform enrichment to use as features in machine learning models – or spatial feature engineering. They will generally access this data through Python notebooks such as Jupyter and they likely use both databases such as PostGIS well as data warehouses like BigQuery.
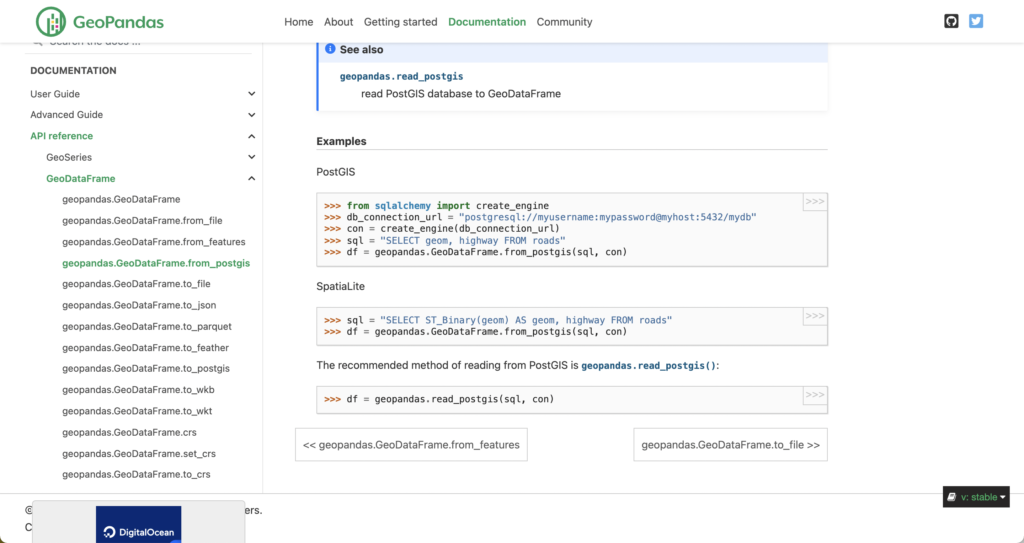
A geospatial data engineer might access and use spatial SQL in any number of ways. They may use it within GDAL to perform operations to transform and manage data within the data transformation process using SpatiaLite. They might use it as a database and a tiling/feature service using pg_featureserv or pg_tileserv. They could also use SQL to transform and join different datasets to create new data, clean and validate data, transform and extract data from different columns, and create datasets for business stakeholders to use. They also use data warehouses like BigQuery to manage and ingest large-scale data using different tools such as Dataflow with geobeam. They use everything from the command line, desktop tools like QGIS, database UIs, Python scripts, and more.
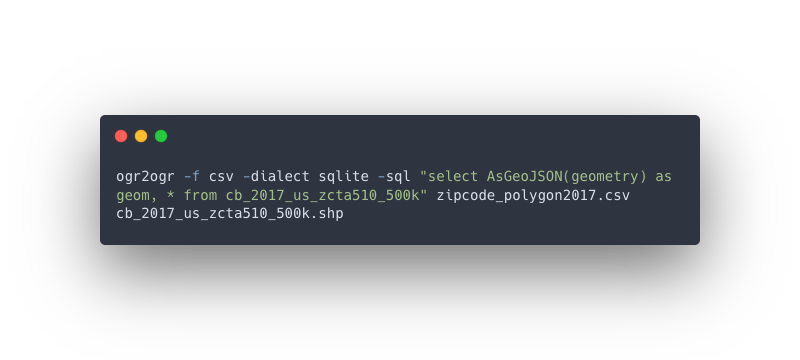
A developer will use spatial SQL databases as tools to serve and save data from frontend applications or other tools that allow users to interact with data from the database. They may interact with the database directly but generally, they use data from the database via APIs or via tiler services such as pg_tileserv, pg_featureserv, or the BigQuery Tiler from CARTO to visualize the data in tools like Leaflet or DeckGL. They will also store data from the application back to the database (if the application requires it). They may also abstract the APIs through tools like GraphQL. Sometimes they will access the database directly, but generally, that is through an API or via Javascript libraries.
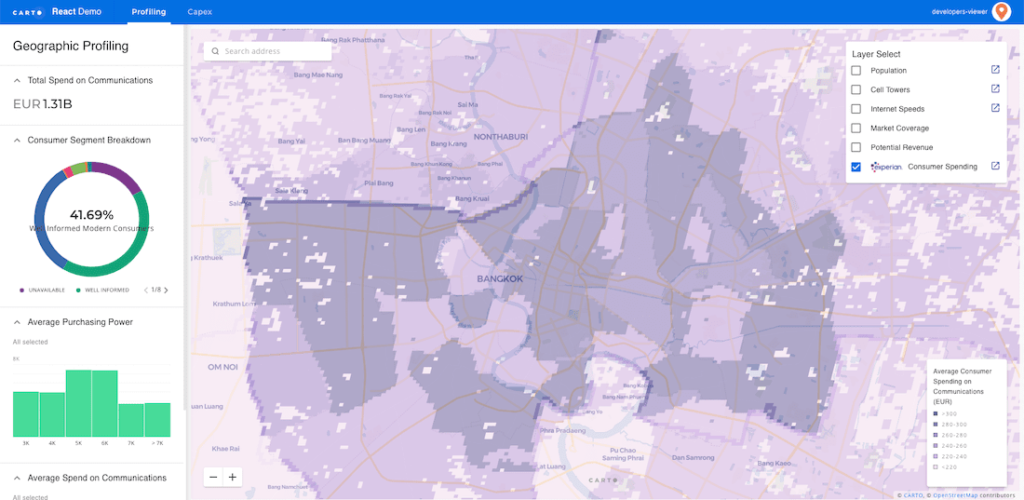
A business user will access the data, sometimes without even knowing it. They may see data from spatial SQL databases in reports, in maps, in user interfaces and applications, in business intelligence tools, and more. They are the end consumers of all the work that has been produced up to this point, and many times the spatial SQL database will be the tool that allows them to access insights faster and more accurately than other solutions.
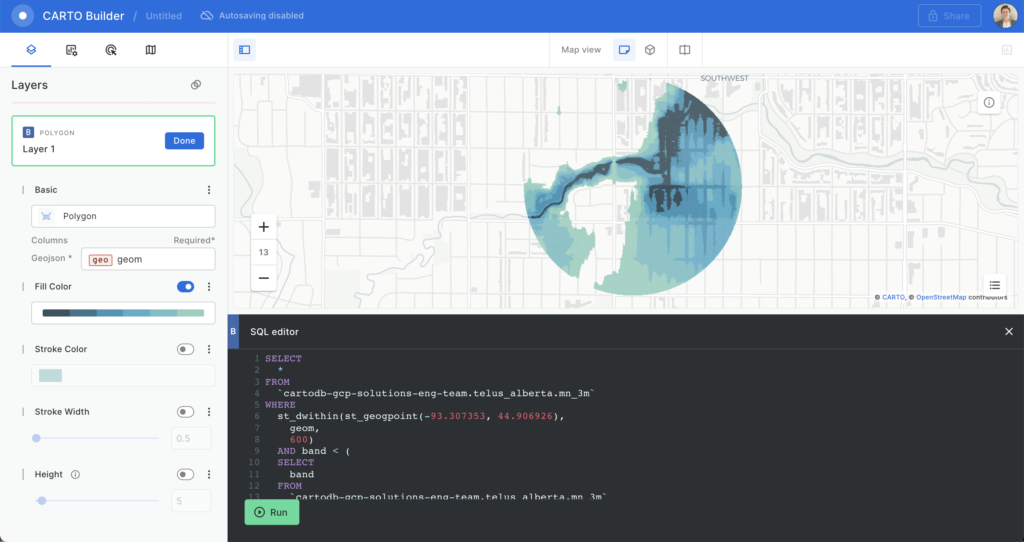
How is spatial SQL more than just SQL?
Of course, spatial SQL, as a language, is just SQL, but it can do and enables so many other use cases beyond that, and it is these use cases (and more) that make spatial SQL so unique and powerful.
In both databases and data warehouses alike, you can use spatial SQL to:
- Query and manage spatial datasets
- Manage projections and re-project data
- Store spatial data in multiple formats (WKT, GeoJSON, etc.)
- Analyze and understand many types spatial relationships
- Perform spatial clustering and perform nearest neighbor analysis
- Transform geometries using buffers, Voronoi polygons, and convex/concave hulls
- Calculate distances – straight line and using the curve of the earth
- Query and manage 3D data
- Create triggers to change and update data based on different events such as an INSERT into a specific table
- Connect to APIs and other external services
- Create user-defined functions in other languages such as Python, Javascript, and SQL
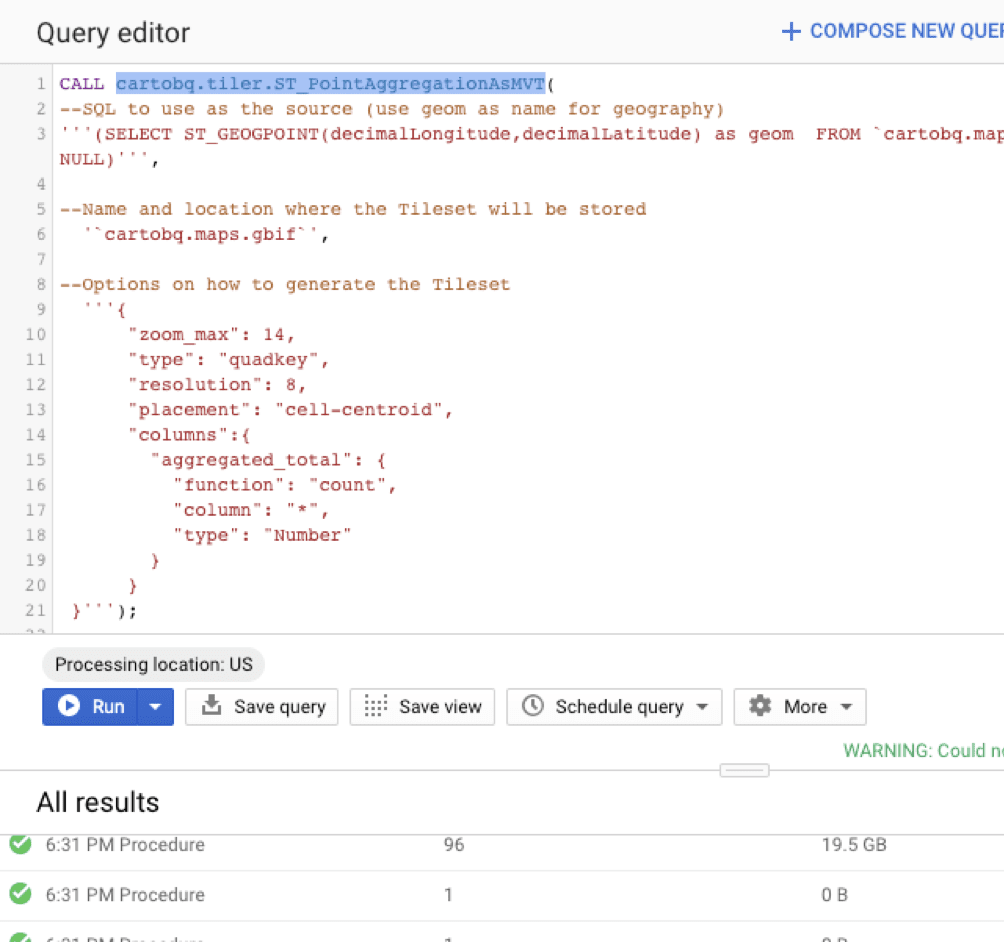
- Perform statistical analysis and machine learning using functions and tools like BigQuery ML
- Store and manage unstructured data like JSON
- Return data in many formats such as GeoJSON or Shapefiles
- Produce and generate map tiles for frontend apps
Why it matters…
I have been a major proponent of spatial SQL for some time now, and that is because it not only has helped me do things that I could only conceptualize before, but also that it gave me more tools to work with larger data, do analysis with more freedom, develop complex applications, and more. And it continues to expand all the time, but for me, these are the key value propositions of spatial SQL:
Interoperability and repeatability
SQL is a common language that can enable the same method of communication across all the roles listed above. Previously these were separated not only by different languages, but also tools with different requirements and training.
SQL is SQL for everyone and every role. It means that the same person across your teams and organizations can compete and use (over and over) the same queries and code. At CARTO this happens all the time. Everyone from on our Product, Services, Solutions Engineering, Data Science teams – and even members of other non-technical teams – use spatial SQL allowing for us to easily share and collaborate, but also make our work repeatable since the queries can be saved and reused as needed.
Efficiency and speed
Spatial SQL is fast. I can almost guarantee that you can speed up a significant part of your workflow with spatial SQL no matter what other tools you are using. This applies to simple queries and up to large-scale data. And if you plan on working with other datasets with complex small geometries (think granular raster data), data that is constantly being added or changed to a historical log, or data in the billions of rows, then a data warehouse can provide you spatial functionality all with spatial SQL.
Speed of course is one component of this, but it is also the flexibility to easily and quickly pivot or change your analysis. By changing a table name, I can change the table I am using in a spatial join and re-run the query. Need to change a numeric column to a string, just cast the column, Want to manipulate other data in your datasets? There is always a function to do so. Imagine having to do that in a point and click interface.
Ensure cross-functional collaboration
One problematic issue in GIS is the fact that for years GIS teams worked in silos, many times because of the proprietary tools used in GIS that couldn’t connect with other tools and data systems. SQL however solves that problem. Many non-spatially focused teams (such as analytics, data science, and business intelligence) use SQL in their day-to-day work. They can share SQL that allows you to access their non-spatial data to use in GIS workflows, and vice-versa. Problem solved.
Work with large scale data
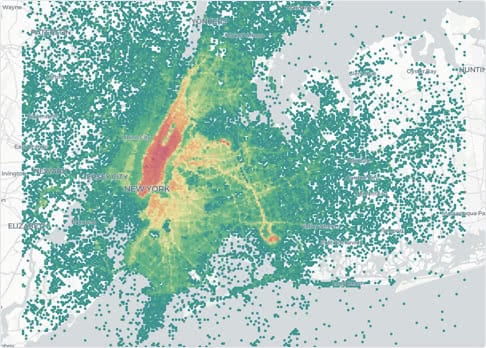
I mentioned this above but the scale of data you can analyze and work within spatial SQL is a key advantage. I recently ran some tests running a spatial join (see above post) between some point data (4 million taxi pick-ups in New York City) and US Census Block Groups. In QGIS I could only use about 5k of those points and the join still took 20+ minutes. You can see the performance of spatial SQL below and make your own decision.
Support use cases beyond the database
Beyond the advantages on the database, spatial SQL offers so many other supporting elements that help you perform tasks for data science, application development, and more. There are tons of services for querying data via common libraries like Python. There are packages that are ready to use to build REST APIs, tile servers, feature services, and more all within your spatial SQL database to help you scale applications. Data warehouses are getting in on the game with tiling services and other advanced use cases like machine learning in BigQuery ML. The ecosystem is only growing, and the best news, you don’t have to move your data anywhere since it is already in the database.
Ready to get started?
Take a look at my favorite resources for learning spatial SQL and this page for more tutorials on spatial SQL.


