
The case for using spatial SQL

Why spatial SQL matters and how it can help you accelerate your GIS and geospatial workflows
Originally published on Towards Data Science in June 2021

It was the spring of 2012 and I just had my first encounter with a SQL query.
I had just moved to New York at the end of 2011 and I was spending an afternoon at the CARTO offices to get a demo of their platform. Javier de la Torre, the founder of CARTO, showed me all about the amazing tool they were building to upload, visualize, and publish maps on the web.

The Spatial SQL Book – Available now!
Check out my new book on Spatial SQL with 500+ pages to help you go from SQL novice to spatial SQL pro.
And then he hit a toggle on the screen and told me:
And here you can write any query you want in PostGIS and immediately have it show on the map!
SELECT * FROM us_states
This was the first time I had ever seen a SQL query, and while I didn’t know it at the time, that simple statement would become such an integral part of my day-to-day work in the years ahead and would help grow my skill set in amazing ways.
Over the years I have become a major advocate of spatial SQL, and I believe it has been one of the most important skills I have invested in. That said it can seem daunting to get started.
To use spatial SQL you need a solid base in regular SQL while also understanding the nuances of spatial SQL — and no doubt this takes time. But in the end, the return on investment makes up for it: you can be more efficient and you gain a ton of freedom as you will never have to depend on any tool or interface to analyze or manipulate your geospatial data.
What is spatial SQL and why is it different than normal SQL?

Great question! Spatial SQL uses all the same elements and structure of normal SQL but allows you to work with another data type: a GEOMETRY or GEOGRAPHY.
- A GEOMETRY is when your data lives in a projected coordinate system or a flat representation of the earth
- A GEOGRAPHY is where your data is represented as spherical coordinates on Earth (or some other place such as Mars). You can read more about the differences between the two here.
With these new data types come a set of functions, commonly predicated with ST (such as ST_Intersects) which stands for spatial type.
Many databases offer spatial functions such as:
- PostgreSQL with PostGIS
- Microsoft SQL Server
- MySQL
- SQLite with Spatialite
- Oracle Spatial
As well as data warehouses such as:
- Google BigQuery
- Snowflake
- AWS Redshift
Join other geospatial professionals in my once a month newsletter
[mailerlite_form form_id=2]
Now, why should you learn spatial SQL?
Personally, it both enabled me to do almost anything that I can think of with spatial data and non-spatial data. If I can think it, I can do it with spatial SQL. It also means that I am never dependent on any single tool or data management solution. If you have your data in a database with spatially enabled SQL, you can do everything you need to.
In short, it makes your work with spatial data more efficient, repeatable, and scalable.
Who should learn spatial SQL?
Personally, I think anyone working with spatial data should have some experience working with spatial SQL, but there are a few groups that should definitely invest some time in spatial SQL:
- Teams working with data in SQL based databases such as PostgreSQL/PostGIS or spatially enabled data warehouses
- Spatial data scientists or data scientists using spatial data
- GIS users looking for more flexibility in their analysis and workflows
- Frontend developers creating apps using spatial data, specifically with maps
- Analysts looking for more flexibility from traditional model building tools or software
- People in organizations that deal with lots of data that may have spatial components (place name, address, lat/long, etc.)
What are the advantages of spatial SQL?
There are a few key areas that I will address that will hopefully convince you that learning spatial SQL is a worthwhile investment:
- Be more efficient in your everyday workflows
- Ensure repeatability within and outside your organization
- Work cross-functionally in your organization
- Create efficient workflows and task management
- Work with large scale data in SQL enabled data warehouses
Let’s break down each of these in detail:
Be more efficient in your everyday workflows

Source from GIPHY
There are a few different ways that spatial SQL can make your work more efficient. Instead of loading and reading files as in a traditional GIS workflow, the data is already there. Even if you need to load data, there are many tools to help you do so and to update data as it changes. No need to read new files every single time you start a project, which can be beneficial as your data gets larger.
On the “Spatial SQL — GIS without the GIS” episode of the MapScraping podcast, Paul Ramsey talks about the advantages and inevitability of learning and using SQL in GIS:
There is no doubt that if you want your career to progress beyond…abstraction that has been provided by you by some other programmer, you are going to want to learn SQL…
In addition to this, there is also the flexibility of SQL. Let’s say you want to return a query that contains:
You can always create new features with spatial SQL and join/aggregate your data on the fly:
- The lat/long of a polygon centroid
- The distance to another point
- Join values from another table
This is easily accomplished in a single query:
Not only that but you can join other data (spatially and non-spatially), limit and filter data, and more all within a query. In a more traditional GIS workflow, you would need something like a model builder to accomplish this.
In Python, you can perform a lot of the same functionality, specifically with spatial relationships, with Geopandas. But at scale, you will generally need to add some other libraries to match the performance of PostGIS or another SQL database.
Not to mention that in many spatial databases you can create indices on your geometries to make operations and functions that use the geometries run faster.
Ensure repeatability within and outside your organization

Source from GIPHY
One great thing about SQL is that it is very portable, meaning code snippets can easily be shared amongst your team.
When someone writes a really great query or chunk of a query, you can share it and anyone (as long as they are on the same database and have access to the same tables) can use it, something that happens on our team at CARTO at least once a week.
Doing the same with something like a model builder means not only passing files back and forth but also model files and other data. Additionally taking just a chunk or part of a mode and adding to your model isn’t as easy as simply copying and pasting a chunk of SQL code.
Not only that, but you can take advantage of a wealth of information online that has been shared by other SQL users online. There are endless resources from blogs, StackOverflow posts, Gists, and more from the spatial SQL community that is at your disposal.
One example that I have used time and again is from this post by Paul Ramsey, one of the creators of PostGIS, on how to run bulk nearest neighbor queries.
In short, it shows that you can do things quickly and make them repeatable, and provide code for others to use and expand on.
Work cross-functionally in your organization
If you work in an organization where you perform GIS or geospatial analysis along with other teams performing non-spatial analysis, then you know the potential that can be created when you bring those worlds together.
The idea of “going where the data is” applies here as most teams store production-level data in some sort of SQL database.
By ensuring that you can work seamlessly and cross-functionally means that you are not limiting yourself to just the data for your team. You can also bring valuable spatial expertise to other teams to learn from and vice-versa.
An example of this would be a retail company that stores transaction data about individual purchases at different stores. Using spatial data you can create trade areas with customer demographics to join with the customer purchase data to see how different demographic features might impact the performance or demand of different products.
Create efficient workflows and task management
One of my favorite things about SQL and databases is how extensible they are for different tasks:
- Update records with an UPDATE statement as new data is available
- Using triggers to set up actions based on events happening in specific tables
- Use an index on geometries to make spatial relationship queries faster and more efficient
- Create your own function with user-defined functions
A very simple example, but let’s imagine that you have a table that regularly has new data inserted into it, and you want to create a geometry from a latitude and longitude field in the data and calculate the number of locations from another table within a certain distance.
With a trigger in PostgreSQL you can set this up one time and (for the most part) never have to worry about it again.

Source from GIPHY
Work with large scale data in SQL enabled data warehouses
Data warehouses are becoming common in many organizations small and large because of their ability to quickly query large datasets in a common data repository. You can learn more about data warehouses here.
The major data warehouses — such as BigQuery, Snowflake, and Redshift — come preloaded with many spatial functions for you, ready to use. In addition to spatial functionality, you can also use machine learning workflows like BigQuery ML and platforms like CARTO are bringing additional functionality for spatial analysis and visualization via the Spatial Extension directly from the data warehouse.
To highlight the speed of data warehouses you can see a sample query below that counts the number of building from OpenStreetMap that fall within each US Census Block Group.
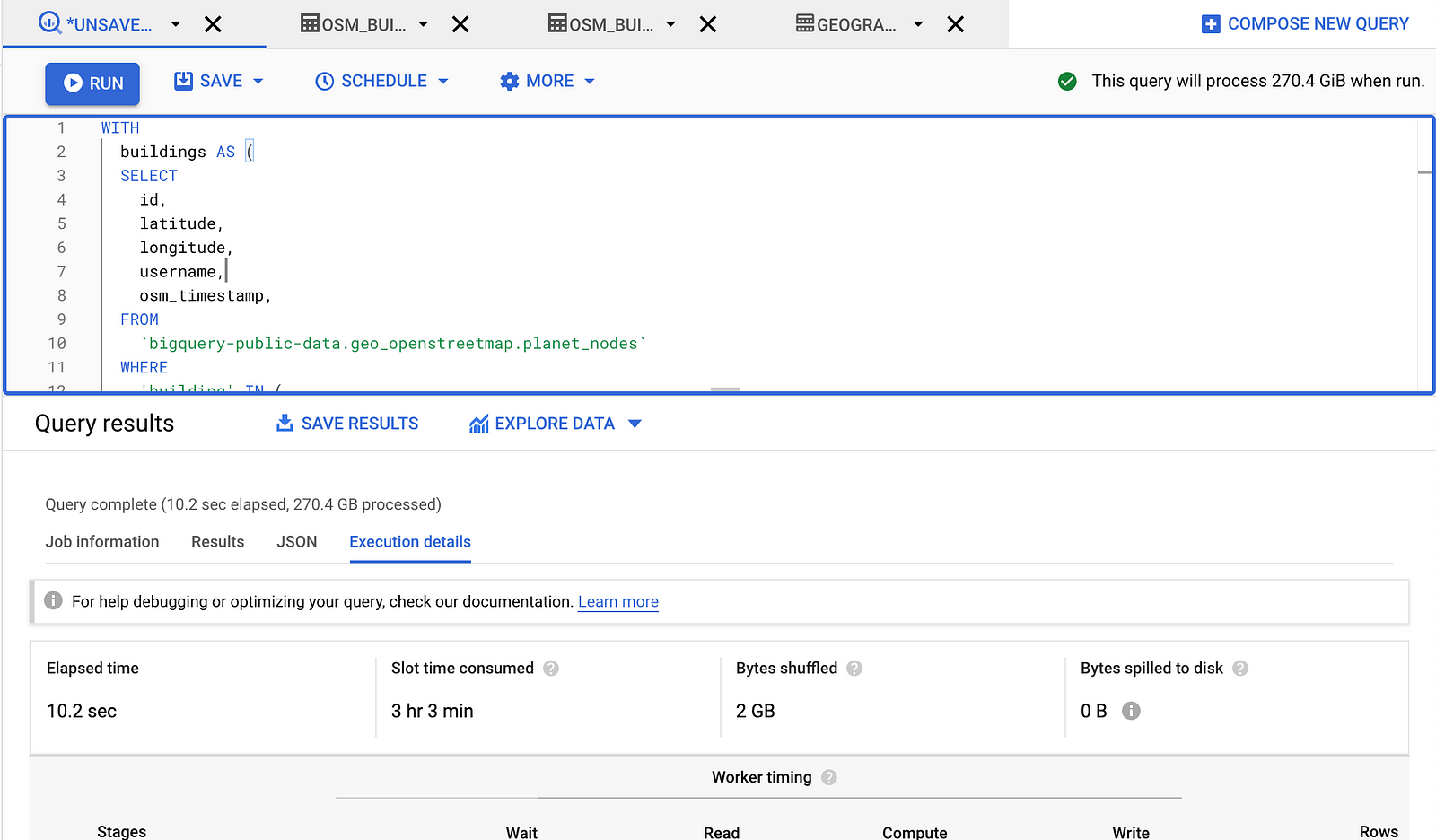
I hope that this inspires you to try spatial SQL for yourself and I plan on following this up with a few more tutorials as well!


