
How Cloud Storage Powers Cloud-Native Geospatial, AI, and Analytics

Look we can throw around a lot of terms about cloud-native and how geospatial is moving to the cloud, but none of this happens if it isn’t for cloud storage.
Yes, this post is going to talk about storage. It’s one of the fundamentally more vanilla topics when discussion the cloud. When you boil it down all it does is give you a place to store data.
But if you look a little closer you can see why it has spurred cloud adoption across industries. It is what makes cloud-native geospatial feasible. And storage of all things is what will enable a major shift in our industry.
But first…
Do you have to store your data in the cloud?
No. If you don’t need to share your data with anyone else, or if you just need to share it with a few people, scaling up your cloud data program doesn’t make a lot of sense.
I can’t remember the exact post or person who shared it but there was a response to a LinkedIn post about cloud-native geospatial that said something along the lines of “why wouldn’t I just put my data on a hard drive and send it to someone rather than pay for cloud storage, if I only need to share it with that one person?”
Apart from the obvious costs of the drive and time to share the data, this is a totally reasonable solution. I am not here to sell you on the need to move all your data to cloud storage.
What I do hope to show is why storage unpins the surge in analytics, cloud-native geospatial, and AI. Yes, simple and understated cloud storage.
NEW CERTIFICATION – CLOUD NATIVE GEOSPATIAL
I have started building out some new certifications aimed at enabling anyone to get a validated certification in modern GIS and geospatial skills. I just launched the first one focused on Cloud Native Formats and Cloud Storage.

You can find out more about the program here and the three other bricks in this track using this link or if you want to sign up for the first track right away you can do so here.
Cloud storage is a cloud-primitive
I actually picked up this term when I was listening to the Acquired podcast episode on AWS a year or so ago. Shockingly it is a seriously underused term but one that made so much sense when it was used in the context so I went back to the episode and fortunately enough they publish their episodes with complete transcripts (you can find that here):
It’s actually a really good interview that Andy (Jassy) does with Harvard i-Lab in 2013. That’s on YouTube. They’re talking about the origin of AWS. I think the topic is intrapreneurship at companies, which is my God, the most disgusting word of all time.
Andy in the talk, he’s like, well, we had to decide, as part of this vision document and the discussion around it, how do we launch this? Do we pick just one service, one IT primitive, and launch with that? Or do we put together a whole bunch of things and launch them all together? He says what they ended up doing was they got a tiger team together of the 10 best technical minds inside the company.
They deconstructed all the major web services, web applications of today, amazon.com itself, Google, eBay, he doesn’t mention them by name, but I assume the other big web services of the time, big web applications, and then figured out what you would need to re architect those services based on this new cloud IT primitive infrastructure. They come up with a list. They decide you need storage, you need compute, you need databases, and you need a content distribution network, like what Akamai was to be able to recreate any internet service of scale.
While I highly recommend listening to the episode (and many of the other episodes as well) what this points out is that these services are the building blocks of the cloud, and many other cloud services are actually built right on top of those services:
- Compute or AWS EC2 (Elastic Compute Cloud)
- Databases or AWS RDS (Relational Databases)
- Storage or AWS S3 (Simple Storage Service)
- CDN or AWS CloudFront
Storage started as the place you used to store any file you needed to access in an app online: image, PDF, video, etc. all got stored and served from a cloud storage bucket.
But over time…
Storing data became the default for apps
All these apps ended up collecting massive amounts of data about how users were doing things. I am not talking about things that would go in a database, like the email of a user or the location of an Airbnb listing, but actions that were taken in the application.
We are also not talking about a few actions but many actions taken all the time – today that can equate to billions or trillions of actions. And all this data was being collected and dumped into cloud storage buckets (why that didn’t cost an arm and a leg will be shared later) to be used to understand user behavior and make improved decisions via analytics, data science, and machine learning.
And now that companies found out that there was value in those blobs of data that systems were built around it to help analyze it. Both in terms of processing systems, data formats, analytics tools, and orchestration.
Cloud storage actually gets cheaper over time
Now it may seem that it would be quite expensive to store all this data, especially since as applications add more users and more functionality that the cost would grow significantly over time. But cloud storage costs kept getting lower and lower over time, and although not as clear as Moore’s Law on the compute side, you can see that storage costs keep getting cheaper over time.
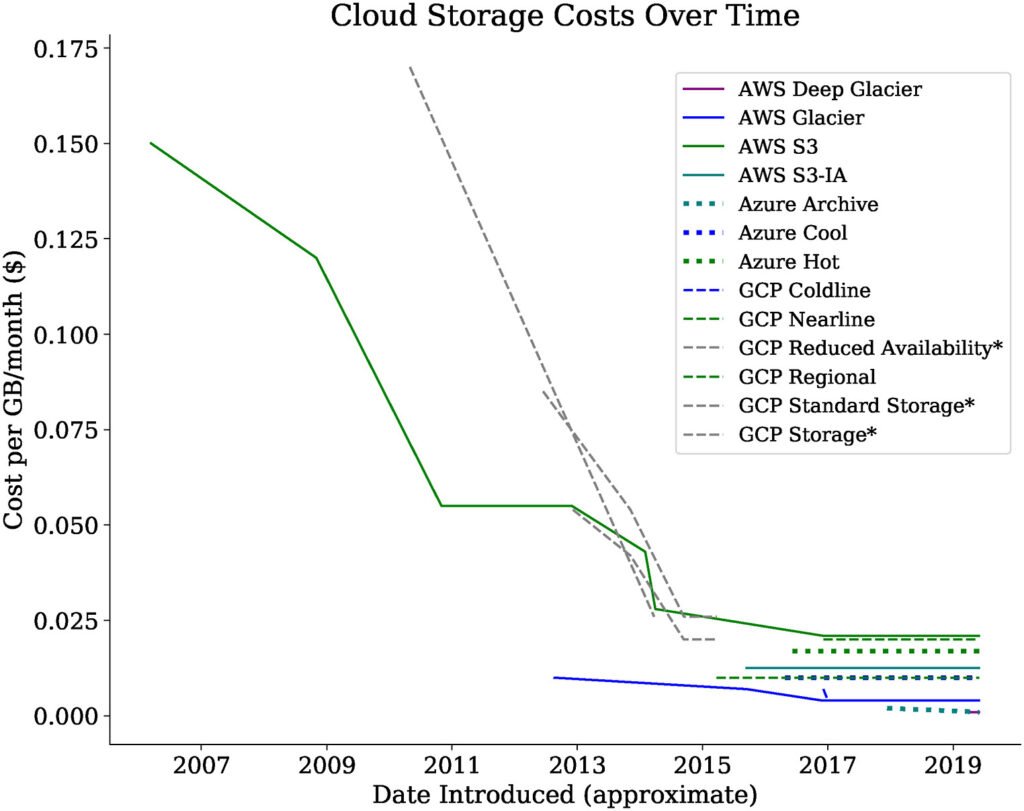
This means that companies could store more and more data at marginal costs. Now that they have all this data how do they process it.
This brought about all the tools to make use of this data. Apache Spark. Snowflake. BigQuery. Databricks. Apache Airflow. Apache Superset. Trino. Apache Iceberg. And on and on.
Please, what does any of this have to do with geospatial?
Right. So there are two major advantages that these systems, both the storage and the processing layers, enabled:
- Cheap storage of lots of changing data
- Ability to leave data where it sits
Geospatial and GIS data has not done a good job of either of these things. Most geospatial data is stored in a single node system that also requires a compute layer. That could be something like PostGIS, Esri Server, GeoServer, etc. This in part has to do with the need to make visualized tile layers but not always.
When the data storage is coupled with a compute layer it nearly guarantees expensive data storage. Not all data is this way. Many government datasets are provided via an HTTP server but that doesn’t help the second step which ensuring you can leave the data where it sits.
Having data on cloud storage with open access makes it far easier for the query engines mentioned above to connect to the data. HTTP data or open data that requires an email sign up to access API doesn’t solve this.
Not to mention that some of the datasets that have the most value and change the most have their own set of issues:
- Rasters: Creating mosaics, missing data, boundary issues
- Climate: Varying formats, scale, consistency, required account creation
- Mobility: Map matching algorithms, velocity, routing engines to scale
What does all this mean for me?
If you are a user of geospatial data, look for cloud native datasets that are already in cloud native formats that you can start to use in your workflows.
This means that you can connect to these datasets and analyze them, even retrieve them without downloading them, or query them and download just the parts that you need.
Source Cooperative and AWS Open Data are great sources of this data if you are looking to get started.
Finally look at different engines that will enable you to consume this data. The list is growing all the time but check out the websites for COG, GeoParquet, and Zarr for the most up to date lists.
If you are create or publish geospatial data then you should definitely look at how you can create cloud-native geospatial data.
If you need some help check out this guide or my new mini-course that can certify you in creating GeoParquet and Cloud-Optimized GeoTIFFs efficiently.
If you are create or publish geospatial data then you should definitely look at how you can create cloud-native geospatial data.
If you need some help check out this guide or my new mini-course that can certify you in creating GeoParquet and Cloud-Optimized GeoTIFFs efficiently.
What’s next
In my next post I will talk a bit more about the specific cloud native formats and what makes them unique and highlight a specific use case for each, then talk about creating scalable and repeatable data pipelines to ensure you can create and consume this data with ease.